
If you’ve read all our Whitepapers so far, you have read about Features and Features Models and also about variants not being versions. But there is something still missing: configuration management for proper product line development has not been touched yet. This article tries to fill in the missing pieces.
Can configuration management for product lines be a complicated matter? That’s a definite YES! Does it have to be a complicated matter? Not at all! And it would be correct to say that there is no (important) difference between configuration management for single system development and for product line development, unless you do it wrong. But I have serious doubts you’ll find this a sufficient and useful answer. So, let’s have a more thorough look.
Misuse of configuration management systems and its problems
At first, I’ll point out the biggest mistake you can make when implementing configuration management for product lines to misuse it as a variability and variant management system. Typically, configuration management systems (aka version control systems) provide a concept known as branching. That means, a copy of a set of artifacts is created and subsequently changed independently from its original. Branching has a number of proper uses (we’ll get to these later on) and one fairly improper use: branching as the central concept for managing variation in a set of reusable assets.
If a variation is handled by first creating branches, and then either the original or the branched artifacts are being used to differentiate products, there will be (unnecessary) overhead in most cases when compared to other reuse approaches, because typically the branched artifact (for simplicity we assume a single file has been branched) will not be changed completely, and a certain (often quite large) amount remains identical between the original and the branched copy.
Problem 1 – How do you know what is being used, and where?
Now assume a problem has been found in the branch or in the original (let’s assume it has been found in the original). The fix is made and checked into the version management system. So far, so good. Now we have to do something about the branch. First of all, we have to be aware that there is a branched artifact in use in some products for which we have to consider the fix. Some of the version management systems support you in finding related branched artifacts in case of a change in some of the branches. That sounds good. But the problem is: the fix has been found in some part of the file which looks identical in both the original and the branch, so it seems easy to simply copy the fix. That might not sound like a problem, but it definitely can cause issues.
Problem 2 – How do you know that applying a fix is the correct thing to do?
Hold on! How can you know that this part of the file is allowed to be changed in the branch? The managed granularity of the variation is in the file, so there is no easy way (for a version management system or a human) to know if identical entities in the original and the branched file (e.g., lines in the file) are supposed to be identical (not part of the actual variation, hence should be shared) or if some of the entities actually belong to the variation (as intended at the point of branching) and may not be changed.
An example for this phenomenon would be a constant parameter to configure e.g., a buffer size. If the parameter is used by both the original algorithm and a modified algorithm in a branch, changing it in the original implementation does not necessarily imply the need or even permission for a change of the same constant for the modified algorithm in the branch copy. Hence, you have to check which part of a fix can be applied to branched artifacts even if applying the fix technically creates no conflicts shown by the version management. In case of proper automated test suites, you would have to run the test on all products containing the merged artifact to make sure no product is harmed. In all other cases (for some domains automated test suits are not possible), it is basically human guesswork.
Problem 3 – Shared and non-shared assets vs. change sets
This discussion does not apply if the branched artifacts essentially represent a variation and contain (almost) no shared code. That means the variation is properly encapsulated at the granularity of files. In this case a file is either shared or not shared among original and branched copies. If this is known for all files, you only have to deal with the problem of change sets containing both changes to shared and non-shared files. You have to break these up into change sets which are related to shared files only and change sets specific for a single branch.
For change sets with shared files, the change has to be made for all instances where it is shared. If you later create a branch of a copy from a previously branched copy, it gets complicated if the branched off copy is shared with the originating branched copy, but this is not shared with the original. Once again it gets complicated to track this in a version control system.
Problem 4 – It does not happen only on file
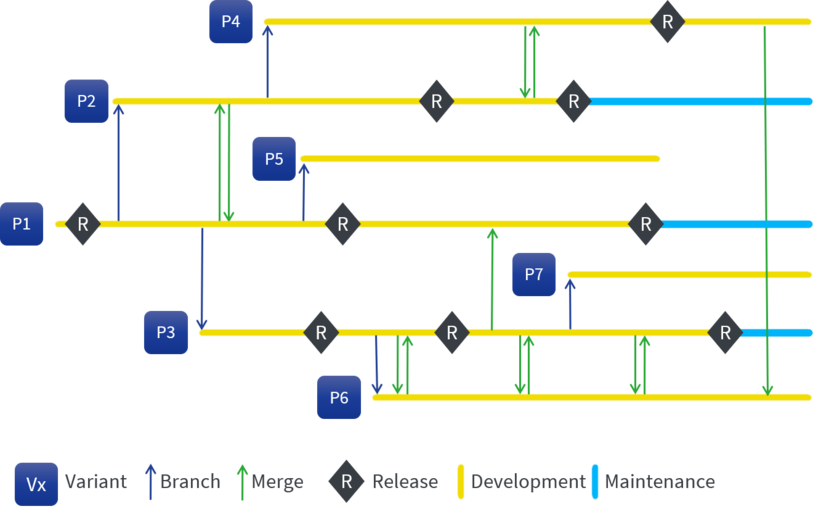
So far, I have been talking about one file, but in reality, there are hundreds or even thousands of files for which this problem can and will happen. And the work increases dramatically with the number of branches, since for each change you have to go through the same routine for each branch. This might work okay for a small number of shared artifacts and a small number of branches, but the former limits the number of reusable artifacts and the later limits the number of variations. Drawing a picture of such a scenario makes the complexity visible: The following graphic shows a typical (simplified) branching/merging log derived from a version control system (time is progressing from left to right), used here to implement seven products (P1-P7) using a typical "branch&merge" strategy of creating clones of an existing system and maintaining them independently later on. It becomes apparent that keeping all branched instances in sync with changes is quite a task. Due to the efforts required to do the merges, only "pair wise" merges happen in most cases, picking some parts from another product. Systematic reuse looks different.
Conclusions about the misuse
To sum it up, unless the granularity of the version management artifacts is more or less identical to the granularity of the variation, branching in version management is not good for expressing variation points. So, no matter what your version management system vendor tells you about how good the system can handle variation, watch out for mismatch of granularity. And in case of file artifacts, it is almost inevitable to have a granularity mismatch. But do not get me wrong: You have to use a proper version management to track changes to your artifacts over their life time! However, variability and variant management should not be mixed into it. Variability is a separate, orthogonal dimension expressing what is available for use and being used in variants at a given point in time.
Proper use of configuration management systems for product lines
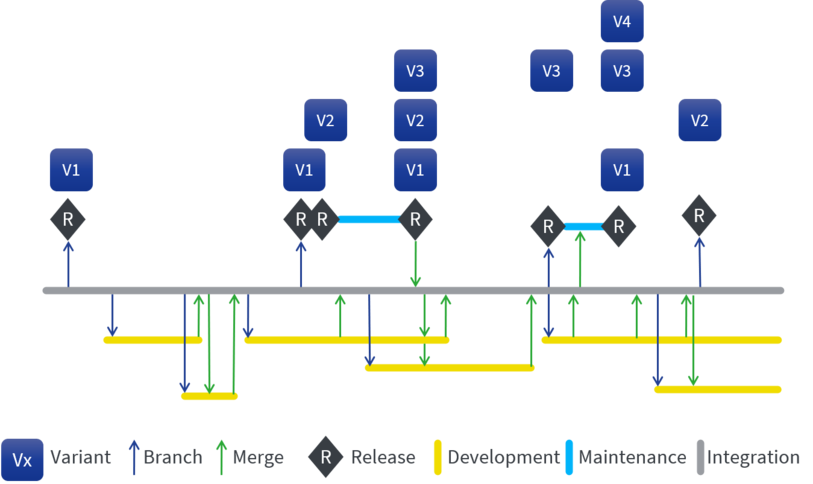
If you are wondering now what branches are good for in product line development, it is simply the two things they are good for in single product development: for short term decoupling of independent development activities from the main development branch (often called "feature branches"), and for decoupling a (soon to be) release from the ongoing changes on the main branch (often called "release branches"). A good description of both concepts can be found in the freely available Subversion eBook (the descriptions are mostly independent from Subversion, just replace "trunk" with "main development branch"). Application of these concepts creates a much cleaner and nicer picture. The branches above the main development stream, in the picture below called "Integration", represent branches created for releases, and the ones below are used for developing new functionality. In general, branches are much shorter and merging is done mostly from development branches to the main (integration) development stream, rarely from/to release branches.
This approach not only makes for a nicer drawing, real reuse becomes much easier to achieve too. Instead of products, you see variants (V1-V4) in the picture, derived from a common base. The actual derivation of variants from the shared base is executed as an independent activity, usually by means of configuration or use of proper variability and variant management tools like pure::variants. The point is that this derivation/instantiation activity is done on top of version-controlled artifacts, so the version control system might be used to record the instances, but does not provide the variation point mechanism.
Summing up
This brings me back to my initial claim: If representation of variability and variants is not implemented with version management (which is a good idea, see above), there is nothing special about version management when it comes to product lines, except maybe for performance and scalability (due to more users and more changes).